The identity of a Microservice

My current company is undergoing a transition to microservices. This is a new challenge for the company since, until this point, all our processes and tooling revolve around a monolith, shaped by all the decisions we made in the past (the good ones and the bad ones).
The way we decided to start is by migrating one single component into a microservice, and laying down a “golden path” for other services to follow. This is helping us streamline the process, and kicking off some really interesting discussions about the topic.
Today was the last big debate. 15 people in a room, all with different backgrounds, debating whether it made sense for us to deploy a service to 2 clusters of machines (one serving the HTTP API and the other listening to different event streams and materializing information to the database), or to a single cluster of machines with those 2 responsibilities.
The outcome of the debate was pragmatic and the right fit for our current needs, but I was surprised to discover that we could not agree on one of the most basic aspects: When does a microservice stop being a microservice?
I was going home and I couldn’t shake the thought out of my head, so I decided to write this (highly opinionated) article. Hopefully it will resonate with some people, and some comments will challenge my current assumptions.
Setting some boundaries
One of the first concepts we learn when doing microservices is the concept of bounded contexts, or boundaries between two different parts of our business. Setting the right boundaries is really hard, because all the parts of a business are interconnected one way or the other. But let’s say we’ve found a reasonable approximation to a bounded context, and we have a service P which handles payments.
Service P (as you can imagine) is quite popular in the company. And it has a lot of other components that want to talk to it, so it needs to define a way for them to speak. That’s the interface, or the API of the service.
A foreword on interfaces and sharing the database
Now, us, the people who work on Web Services, tend to associate the term interface with a classical Java interface, and the term API with a REST HTTP API, but for this article’s sake I would like to emphasize that an interface can be ANYTHING!
- It can be an series of HTTP endpoints.
- A queue where you send job parameters encoded in JSON.
- A series of CSV files in an S3 bucket.
- A SQL database.
- Your colleague Mike, owner of the script you need to run when a customer calls you with that problem.
If you work on backend/frontend, chances are you’re used to options 1–2, and options 3–4 sound deranged. If you work on data, you’re probably doing 3–4 quite often. And if you’ve been in the industry for a while, you’ve probably experienced the pain of option 5.
But the point is, they are all interfaces, and they all make sense given the right context. The important part is to find a contract the client can use, and the server can guarantee.
So I think when we hear one of those strong statements about microservices, we should put it into context.
Myth: “2 microservices must not share the same database”
Reality: “2 microservices must not share the same database to store internal state”
The logical and physical interfaces of a microservice
I usually look at a service’s interface from two angles.
On the one hand, we have the “logical” interface. This is comprised by the way the inputs and outputs are structured, or the way we name and organize different endpoints, commands or tables.

On the other hand, we have the “physical” interface. This has to do with the way the interface is exposed. How do we address the HTTP API or the Database? Is it exposed publicly or through a private network/vpn?
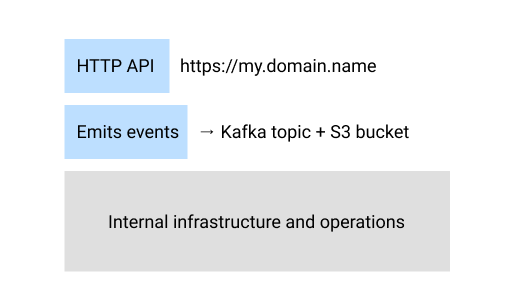
What I’ve come to realize today is that the intersection between the logical and the physical, and between the interface and the implementation details, is a grey area that causes a lot of confusion. So I’m going to ask you some philosophical questions, and as a thought exercise, you can jot down what your first intuition is.
Does a microservice stop being a microservice because we refactor the internal code?
If we carried out an internal refactor of our code, preserving the current interface, would we call it a different microservice?
If we modularized certain parts of the service, would it become something else?
Does a microservice stop being a microservice because we change how we deploy it?
If we deployed a service to multiple regions, or multiple clouds, would they become different services?
If we deployed a service to 2 independent clusters (one handling iOS clients and the other Android clients, for isolation purposes), would that make them different? What if this required implementing custom logic for the load balancer?
If we deployed the same codebase in 2 different flavors (one handling HTTP requests and the other consuming events), would that mean we’re not doing microservices?
If our deployment was composed of 6 serverless functions, 2 HTTP servers and 1 database, all deployed and updated independently, but sharing the same codebase, would you identify them as two separate microservices?
Got your answers?
If your intuition was to answer “no” to the questions in the first section, and “yes” to some of the questions in the second section, I have to tell you I disagree with you. But let me ask for two favors:
- Hear me out.
- Share your thoughts and counter-arguments in the comment section. I’d really like to know!
My (Current) Point of View
For me, a microservice is identified exclusively by the interface it exposes.
How the different code files, modules and variables are laid out internally does not change its identity, and I feel that’s easy to agree on.
But I would argue that the same reasoning should be applied to the physical implementation details. At any point, we may:
- Deploy the service to multiple regions or clouds.
- Split the deployment in each region between 3 clusters, to bulkhead different workloads.
- Deploy version 2 as a canary release, to only 10% of our users.
- Rewrite 2 event listeners as serverless functions.
These decisions will make the solution more reliable. They will also make it much more complex to maintain. But they won’t change the identity of our microservice in any way, nor will they represent an antipattern of microservice architectures.
… Right?